Introduction
While Microsoft Fabric promises a collaborative workspace for Data Analysts, Engineers and Scientists alike, the person with the most to gain, and the least to lose, from the data mesh-like architectural patterns in Fabric is the Data Analyst.
Do you, as a Data Analyst, recognize any of the following challenges?
- Getting your own data into an existing data model is time consuming and/or difficult to achieve (Ingest & Prepare)
- Making changes to calculations, relationships and content in data models is complex or even impossible (Store & Serve)
- Driving actions from insight is difficult due to data quality, availability or reliability issues (Consume & Act)
Then Microsoft Fabric might be the solution for you.
This first part of the article series, ‘Microsoft Fabric for Data Analysts’, explores how you as a Data Analyst can get started with ingesting your own data into Microsoft Fabric.
The article will first establish common needs and challenges regarding Data Ingestion faced by the Data Analyst, then I will outline three different methods for ingesting and preparing data into Microsoft Fabric, and finally I will provide you with a small flow chart to help you decide which approach to use.
Data Ingestion & Preparation Needs and Challenges
Data Analysts commonly want to integrate new data into a model currently used for reporting. Sometimes the data is already in the cloud, and sometimes the data is a small spreadsheet of handwritten data that came out of a meeting the other day.
However, in the process of solving this need, the analyst will often face one or more of the following challenges:
- The data model is created further upstream in tools that the Analyst does not possess the required skills for, or is not allowed to add new data to the model themselves, even if they could.
- The analyst is allowed to make changes, but has to adhere to development, deployment and security requirements that the analyst does not know how to accomplish.
- The analyst must ask Data Engineering colleagues to help solve one or more of the above, resulting in delayed time to delivery.
In Microsoft Fabric however, the collaborative workspace, low-code tools and OneLake integration provides the Analyst with several tools of their own to solve the Data Ingestion tasks on their own.
Ingest and prepare data with Dataflow Gen2
One of the typical scenarios for data ingestion, is that the analyst wants to integrate some new data in the model, which already lives somewhere in the cloud.
This could be:
- Data stored in Excel or CSV files on OneDrive/Sharepoint.
- Data from an existing database you already have elsewhere.
- Data from an API or 3rd party software that you use.
As an Analyst, one tool you can use for this kind of Data Ingestion in Microsoft Fabric is Dataflow Gen2, which is part of the Data Factory Experience in Fabric.
Dataflow Gen2, the revamped version of Dataflows from the Power BI Service (and basically Power Query in the cloud) keeps existing data connector functionality, while improving performance and adding the possibility of Data Output Destinations.
Creating a Dataflow Gen2
To get started with Dataflow Gen2, go to your Fabric Enabled Workspace (regardless of which Fabric Experience you are entering from). Click “Create New”, select “More Options”, and choose Dataflow Gen2 from the list of Data Factory artifacts:


Connecting to Data
In the Dataflow Gen2 editor, you can connect to data from hundreds of data connectors. It works well with Databases, files stored in OneDrive/Sharepoint and even custom API calls, and transformation is as easy as you know it from Power Query on your desktop.

Data Transformation
Likewise, if you want to, it is possible to apply data transformation already at this stage of the data journey, as part of the ingestion. The editor behaves exactly as in Power Query/Dataflows, with the possibility of cleaning, enriching, and structuring data as you’re used to:

If you want a more visual no-code approach to transformation, the excellent Diagram View / Visual Query builder, allows for an easy to understand overview of data lineage within the dataflow, as well as the possibility to add transformations to your queries:


But you may also want to keep your ingestion clean, and only use the transformation tools to filter out unnecessary data, leaving any complex transformation for later down the line.
Adding a Data Destination
What’s even more exciting however, is the new option to output data to a Data Destination. From an easy to navigate GUI its possible to Overwrite and Append data to New or Existing Tables in either a SQL or Kusto Database in Azure, or to a Microsoft Fabric Warehouse or Lakehouse:


Publish and Schedule your Dataflow Refresh
Finally, after selecting the output destination for each table being loaded, Publish your Dataflow Gen2 with the big green button, and watch it perform its first refresh.
If you want this ingestion process to happen automatically on a schedule, the fastest way to do so, is by finding the Dataflow Settings, and setting up a Refresh Schedule, similarly to how you would schedule Dataflow and Dataset refreshes in the Power BI Service:


However, if you want more control and governance around your data refresh, you may further employ the help of Data Factory Pipelines, as outlined in the section below.
Ingest data and/or orchestrate Dataflow Gen2 with Data Factory Pipelines
Another of the Microsoft Fabric tools which you can use for ingestion of data already hosted in the cloud, and is approachable for you as an Analyst, is Data Pipelines from the Data Factory Experience in Fabric.
Data Pipelines are close in functionality to that of Azure Data Factory and/or Azure Synapse Pipelines, without being able to boast full feature parity… Yet. You can use them for complex ETL processes for ingesting data, or as orchestration pipelines for executing various activities (including refreshing your Dataflow Gen2!).
Creating a Data Pipeline
To get started with Data Pipelines, again go to your Fabric Enabled Workspace, click “Create New”, select “More Options”, and choose Data Pipelines from the list of Data Factory artifacts:

Data Pipelines are built up around ‘Activities’, each which may be configured with settings and parameters for altering their behaviour, and which link together, allowing for creating sequences of conditional activities.
Some of the activities requires more complex setup and in some cases the use of coding to function well, but others can be setup completely no code style.
Ingesting data with Data Pipelines
If you wish to use Data Pipelines for data ingestion, your activity of choice would be the ‘Copy Data’ activity:

You can configure it manually:

Or if you prefer, use the Copy Assistant for a more guided experience:

And once your Copy Activity is on your Canvas, the pipeline can be scheduled to run at an interval you determine, and will ingest data into your selected destination automatically:


Improve Governance by using Data Pipelines to Orchestrate ingestion & preparation
The true power of Data Pipelines does however not come to show in single activity pipelines like the one created here. Data Pipelines truly shine when used to conditionally sequence multiple activities, and orchestrate several actions.
One may for example run another Activity after the Copy Data activity Succeeds. E.g., running a Stored Procedure on the Data Warehouse:

Or decide to run our previously created Dataflow Gen2 if the Copy Data activity has failed:

And create further governance by communicating the success/failure of our flows automatically by leveraging the Outlook and Teams activities, or even triggering a Power Automate flow with the Web Activity:

While the above examples only scratch the surface of what a true master of Data Pipelines may achieve with dynamic pipelines, it is hopefully clear how we can use them to provide more granular control of our data ingestion and the governance around it.
Manually loading files into OneLake
On the opposite end of the governance spectrum lies the concept of manually ingestion offline files into OneLake.
Sometimes it is just as valid a use case to bring files from your Local Machine or an on-prem Network Drive into your data solution. And while it is hardly a well-governed and structured approach, it is easily accomplished in Fabric.
With Microsoft Fabric you have two options to do this:
- Install OneLake on your computer and use it like you would use OneDrive
- Upload files directly to OneLake in your Browser
Using OneLake locally installed as ‘The OneDrive of Data’ for manual file upload
Just like OneDrive, it is possible to install and use OneLake in the File Explorer of your computer. Simply download and install OneLake, and make sure to run the application to allow navigating your OneLake.
Once installed, you can browse your OneLake in a neat folder structure, allowing you to see all the items stored in there:

To upload local files to your OneLake you must have a Fabric Lakehouse available in your tenant (we’ll discuss the creation of Warehouses and Lakehouses in the next article of the series).
Then simply navigate to the ‘Files’ folder of your Lakehouse, and copy your local file (preferably in CSV format), into the folder:

And after synchronizing, the files will be available within your Lakehouse:

The final step for ingestion here, is to load the CSV file into a new or existing table, and your manually ingested data will be available for you to use in Data Models built on the Lakehouse:


Using manual file upload directly in Fabric Lakehouse
Alternatively to the approach above, it is possible to upload files directly to the Fabric Lakehouse inside your browser.
To do this, navigate to your Lakehouse and find the “Upload Files” option by right clicking the ‘Files’ folder:

Select the file you wish to upload, and allow for a few seconds before refreshing the Files folder, and the file should show in its contents:

Same as before, you can now load said file into a table, and get on with your data modeling!
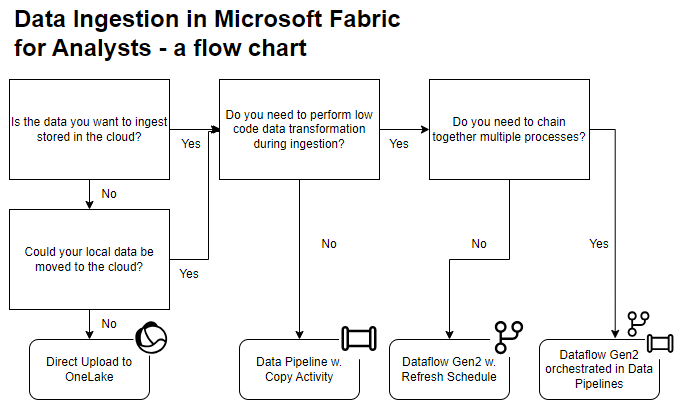
Summary and Decision Tree
This article have shown three different approaches for ingesting and preparing data into Microsoft Fabric as a Data Analyst:
- Dataflows Gen2
- Data Pipelines
- Direct file upload to OneLake
Each approach has strengths and weaknesses, with varying degrees of complexity, flexibility and durability. Below is a quick flow chart which hopefully can help you decide which tool to use for ingesting data into Microsoft Fabric:





Leave a comment