In the past year, I’ve built Conversational BI solutions with many different technical stacks. Fully SaaSified solutions like Fabric Data Agents and Databricks Genie. A self-hosted, open-source analytics agent framework. A custom MCP server which interfaces my Data Platform exposed in Claude.
Each month. Each week almost. It feels like one of the solutions start pulling ahead of the pack. Until next month comes around, and another one has its moment.
Every time, I think to myself, in a seemingly never-ending cycle: I picked the wrong horse! I need to re-evaluate my choice.
Schumpeter had a word for this
During my Bachelor studies at Copenhagen Business School, I had a class on “Managing Innovation Projects” taught by a way-ahead-of-his-time lecturer, Rasmus Koss Hartmann (his Mixed Methods classes, podcast lectures, workshops deserves a whole blog of its own). I didn’t realise its importance it at the time, but the knowledge and articles I was introduced to in this class are the ones I find myself coming back to the most in my professional work today.
My recent ventures in Conversational BI have yet again brought me back in time. This time to perhaps the most foundational text of them all: Joseph Schumpeter, and his writing on the “*perennial gale of creative destruction*“.
While his theory builds on soon-to-be century-old industrial references, I think it perfectly captures the essence of the current trend:
“The opening up of new markets, foreign or domestic, and the organizational development from the craft shop and factory to such concerns as U.S. Steel illustrate the process of industrial mutation that incessantly revolutionizes the economic structure from within, incessantly destroying the old one, incessantly creating a new one. This process of Creative Destruction is the essential fact about capitalism.”
This month’s AI news, upending your current understanding of the world is not a one-time storm. Not a disruption event you survive and then return to normal. You need to understand it as a permanent condition. Old solutions don’t die because they’re bad – they die because better ones keep arriving faster than anyone can adapt.
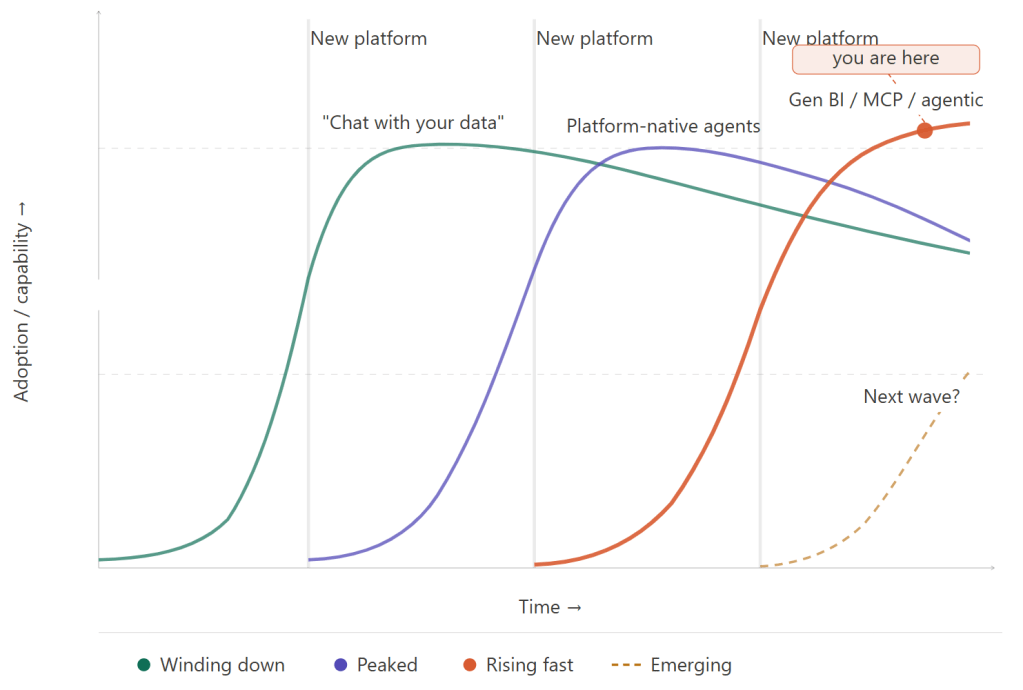
Fate would it, that last week at the Inspari AI & Data Day, keynote speaker Peter Hinssen brought out the exact same parallel about AI / Agentic Development in general, including an example with the famous S-curves. I guess I’m not the only one to notice this, is all I’m saying. But in this week’s blog (and likely a few deep dives in the coming weeks), I’d like to zoom in on the specific topic of Conversational BI, and the innovation we’re currently seeing here.
What exists today
So, if you’ve been building, maintaining or using one of the major data platforms in the past year, chances are you know of their “data agent” offerings, which are also the most easy to get started with:
Microsoft Fabric Data Agents recently became Generally Available (also previously briefly known as “AI Skills”) and allow very easy setup of Data Agents on top of Microsoft Fabric Lakehouses, Semantic Models and Ontologies, with in-tool interfaces for providing instructions and validated queries. Downsides include limited visual possibilities, heavy response size limitations, poor performance and the Fabric capacity consumption is genuinely non-trivial if you have heavy usage.
Databricks Genie adds quite a bit to especially the admin side of things, with a much stronger hold on governance, monitoring and feedback-loops, still within the easily configured realm of the Databricks platform.
Snowflake Cortex Analyst rounds out the three majors. I don’t have sufficient practical knowledge myself to truly comment on its current state, but I am under the impression that it is quite in the same range as Genie.
Outside of the major data platform players’ own solutions, a whole range of external solutions with direct integration to your platform also exists.
They range from 3rd party tools with subscription fees to free Open Source frameworks like like nao. From custom built and hosted MCP Servers used as connectors with your existing LLM vendor (e.g. ChatGPT or Claude) to custom fullstack solutions where you own and customize the frontend too.
I’ll go deep on the trade-offs between these approaches in a future post (Though I suddenly realize the irony of attempting such a comparison when their features and performance change so rapidly). The point I wanted to make here though isn’t the feature list of each tool. It’s that all of them reached some version of maturity in the past year. Or 6 months even. The gale of creative destruction is blowing across the whole landscape at once.
What actually survives the destruction
Before getting to the thing you want, the key tenets you should focus on in times of trouble, I want to be honest: a lot of current Conversational BI implementations are not going to age well. Not because they don’t work, but because what we consider extraordinary today will be taken for granted in a year. The issues you see with one platform, will likely be ironed out before you know it. But you will always want to be on the next, new, shiny thing.
To me the clearest example is how the feature we used to know as “Chat with your data”, which was very much centered around text responses from the agent, is very quickly evolving into “Gen BI” with data visualizations being equally or more important than the text response.
Notice also how this supports that creative destruction isn’t about erasure, but transformation. New structures rise on the foundations of old ones. The foundations that were solid hold.
For Conversational BI these holds exist as well. Below I’ve identified six things that hold regardless of which platform, framework, or LLM you’re using. In order of how they should be considered.
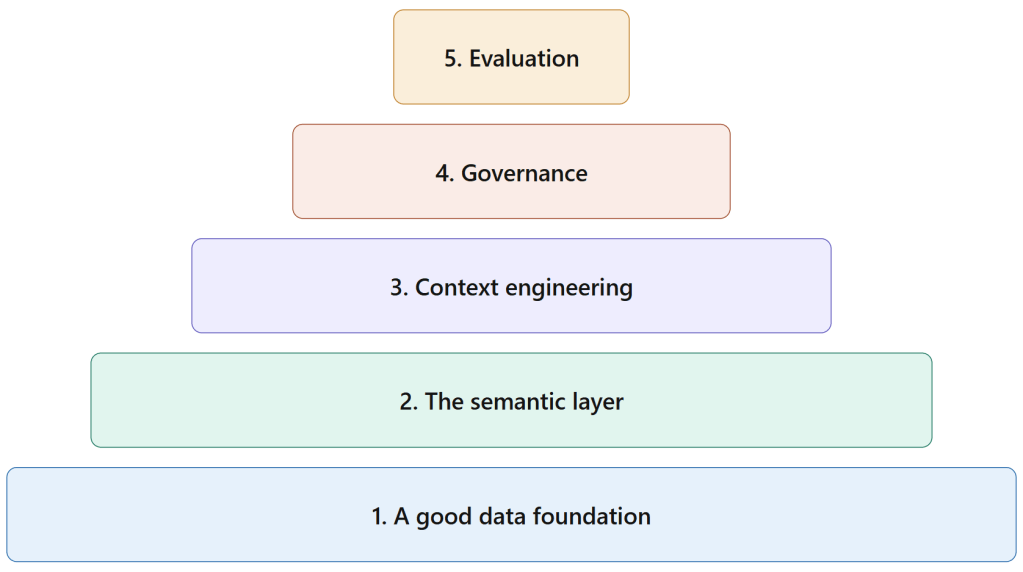
1. A good data foundation
Garbage in, garbage out.
Conversational BI doesn’t fix bad data. Point an LLM at a warehouse full of undocumented views named vw_final_final_v3, useless column names, semantic models with identical measures but different code – and you’ll get confidently wrong answers at a rate that will end the project. Users don’t distinguish between “the agent got it wrong” and “the data is wrong.”
2. The semantic layer
Once the data is clean, you have to describe it. Not to humans, but to the LLM as well.
Whether that’s a Power BI semantic model with proper namings and descriptions, a Databricks Unity Catalog with column-level documentation, or a hand-crafted text file for a custom solution – the agent needs to understand what the data means, not just where it lives.
What does “revenue” mean in your org? Is it net or gross? Does it include returns? VAT or not?What’s the correct table to use for regional sales vs. global sales? Which columns are safe to filter on and which ones are implementation details that should never surface in a query?
Semantic modelers have been building this kind of documentation for years. The difference now is that it directly determines whether your Conversational BI system gives useful answers or confidently wrong ones. The stakes are higher because the output is more visible.
Sounds easy on the surface, but I honestly have not quite figured out myself how to balance this layer with the human-digestible Data Catalog. To me, they are two sides of the same coin. One is interfaced by humans. The other by technology. Both need to expose the same schemas and definitions but not necessarily in the exact same way.
No matter the implementation, your semantic layer is a long-term bet that is not going away.
3. Context engineering
The secret sauce of your Conversational BI agent.
Beyond the semantic layer, every Conversational BI system needs: agent instructions that define scope and guardrails, a business glossary that grounds the LLM in your org’s terminology, validated queries to improve response accuracy, and few-shot examples that shape the output format.
Many PoCs skip all of this and wire the LLM directly to the data. That’s why most PoCs fail to become production systems. Likely because users find the reliability without the context layer to be inadequate.
The critical thing to realize though – and this is why this should be on any organizations must-win battle card – these context artifacts are portable. Agent instructions are Markdown. Glossaries are YAML. Validated queries are (usually) SQL stored in text files. Whatever platform you’re on today, or move to tomorrow, these travel with you. Put them in git. Treat them as the actual product, not as configuration for the real product.
This is the secret sauce, but it obviously still builds on top of steps 1 and 2 above.
4. Governance-first architecture
Who gets to ask what?
Which tables and columns are ever exposed to the agent?
How are queries and responses logged?
What happens when someone asks something they shouldn’t be able to ask, and how do you know it happened?
How do users inform you of bad responses, and how do you improve the solution from there?
The design of your actual governance model. The scope decisions, the access boundaries, the audit trail requirements. They’re yours to define regardless of which platform you’re on. This is the thing that gets skipped in PoCs and becomes the blocker for production rollout.
5. Evaluation and validation framework
How do you know the answer is correct?
This is the hardest problem in the space, and it’s where most early implementations are still flying blind. An agent that gets 80% of queries right in a controlled demo will hit the 20% wrong ones in front of the wrong person at the wrong moment. Demo accuracy and production accuracy are not the same number.
The answer is a testing discipline that most data teams don’t have yet: benchmark question sets with known correct answers, human review for high-stakes query classes, and feedback loops that actually feed back into the context engineering artifacts.
One piece of advice I’d give to myself six months ago
Don’t build your architecture around a single vendor’s framework as if it’s permanent infrastructure.
Not because any of the current vendors are going away, but because what they ship in 18 months will look materially different from what they ship today. The response limitations in Fabric Data Agents will probably lift. Genie will probably get LLM flexibility. Cortex Analyst will evolve. Constraints that feel like architectural dealbreakers today are product decisions, and product decisions change.
Build your context engineering artifacts in portable formats. Version control them. Think of them as the investment that persists across platform changes, not as config files attached to the current tool.
Where to start
If you’re on Fabric, Databricks, or Snowflake and you want something working quickly, start with the platform-native option. Get it in front of real users. Use it to stress-test your semantic layer and start building your context engineering layer while making a gap-analysis of your actual front-end needs.
When you know what you want, write down your priorities:
- Is time-to-response your most important metric? Or is the quality of the response the show stopper?
- Are you okay with simple visualisations, or do you want entire dashboards built in front of you?
- Do you need strong feedback loops, are you okay dealing with a more manual process?
While my decision guide has not been published yet, I’ll let you know already that there is not one correct choice. All solutions have compromises, and we don’t know where the wind is blowing next month.
Build for what doesn’t move. Make an initial commitment. Be ready to move platforms when the market stabilises.




Leave a comment